Teknoloji şirketleri yapay zekanın yazılım geliştirme üzerindeki etkisini nasıl ölçüyor
(newsletter.pragmaticengineer.com)- AI kodlama araçlarının yaygın biçimde benimsenmesi ve artan maliyetler karşısında, önde gelen teknoloji şirketlerinin yapay zekanın gerçek faydasını nasıl sayısallaştırdığını çok katmanlı metriklerle derleyen bir çerçeve sunuluyor
- Temel nokta, mevcut mühendislik temel metriklerini (ör. PR throughput, change failure rate) ve yapay zekaya özgü metrikleri (ör. AI kullanım oranı, zaman tasarrufu, CSAT) birlikte izleyen karma yaklaşım
- Ekip/kişi/kohort bazında AI kullanım düzeyine göre ayrıştırma ve öncesi-sonrası karşılaştırmalarıyla trendler ve korelasyonlar çıkarmaya yönelik deneysel düşünce biçimi vurgulanıyor
- Kalite, sürdürülebilirlik ve geliştirici deneyiminin hız metrikleriyle birlikte sürekli izlenmesi; teknik borç artışını ve kısa vadeli faydaların ters etkilerini önleyecek dengeli bir tasarım için gerekli görülüyor
- Uzun vadede ölçümün ajan telemetrisi ve kodlama dışı iş alanlarına kadar genişlemesi bekleniyor; sonuçta soru şuna indirgeniyor: “Yapay zeka, zaten önemli olan şeyleri (kalite, pazara çıkış hızı, geliştirici deneyimi) daha iyi hale getiriyor mu?”
AI etkisi söylemi ve ölçüm açığı
- LinkedIn vb. yerlerde sıkça görüldüğü gibi, yapay zekanın şirketlerde yazılım geliştirme biçimini değiştirdiği yönündeki iddialar artıyor
- Google 25%, Microsoft 30% gibi örneklerle, büyük ölçekli AI kodunun gerçekten production koda alındığına dair haberler sürüyor
- Bazı kurucular AI’ın junior mühendislerin yerini alabileceğini savunurken, METR araştırması zaman algısında bozulma ve üretkenlik düşüşü olasılığına işaret ediyor
- Medya, AI etkisini “ne kadar çok kod yazıldı” sorusuna indirgedikçe, sektör de tarihin en büyük teknik borç birikimi riskiyle karşı karşıya kalıyor
- LOC (satır sayısı), üretkenlik metriği olarak uygun olmadığı konusunda uzlaşı olmasına rağmen, ölçüm kolaylığı nedeniyle yeniden öne çıkıyor; böylece kalite, inovasyon, pazara çıkış hızı, güvenilirlik gibi esas değerler gölgede kalıyor
- Bugün birçok mühendislik lideri, neyin işe yarayıp neyin yaramadığını net biçimde bilmeden AI araçları hakkında kritik kararlar veriyor
- LeadDev’in 2025 AI Impact Report raporuna göre liderlerin %60’ı en büyük zorluk olarak ‘net metrik eksikliğini’ gösteriyor
- Sahadaki liderler, sonuç baskısı ile LOC’ye takıntılı yöneticiler arasında sıkışmış durumdan memnun değil; ihtiyaç duyulan bilgi ile fiilen ölçülen şey arasındaki fark giderek büyüyor
- Yazar, 10 yılı aşkın süredir geliştirici araçları üzerine çalışıyor; 2021’den bu yana da üretkenlik artışı ve AI etkisinin ölçümü konusunda danışmanlık veriyor
- DX CTO olarak katıldıktan sonra yüzlerce şirketle çalışarak DevEx, verimlilik ve AI etkisi analizlerine öncülük etmiş
- 2025’in başında, 400’den fazla şirket verisine dayanarak AI Measurement Framework çalışmasının ortak yazarlığını yaptı
- Bu çerçeve, AI benimsemesini ve etkisini ölçmek için gerekli önerilen metrik setini sunuyor; saha araştırmaları ve veri analizleri temelinde oluşturulmuş
- Bu yazıda, 18 teknoloji şirketinin AI etkisini gerçekte nasıl ölçtüğüne bakılıyor ve şu başlıklar paylaşılıyor:
- Google, GitHub, Microsoft vb. şirketlerden gerçek metrik örnekleri
- Neyin işe yaradığını anlamaya yönelik kullanım biçimleri
- AI etkisini ölçme metodolojisi
- AI etki metriklerinin tanımları ve rehberi
1. 18 şirketin gerçek ölçüm metrikleri
- Google, GitHub, Microsoft, Dropbox, Monzo, Atlassian, Adyen, Booking.com, Grammarly vb. 18 şirketten örnekler görsel olarak paylaşılıyor
- Şirketler farklı yaklaşımlar benimsese de, ortak biçimde bazı temel metrik gruplarına odaklanıyor
-
1. Kullanım metrikleri (Adoption & Usage)
- DAU/WAU/MAU: Neredeyse tüm şirketler AI araçlarının günlük/haftalık/aylık aktif kullanıcılarını izliyor
- Kullanım yoğunluğu / kullanım olayları: Google, eBay vb. şirketler bunu kod yazımı, sohbet yanıtları ve agentic actions düzeyine kadar ayrıştırıyor
- AI tool CSAT: Dropbox, Webflow, Grammarly vb. birçok şirket memnuniyet anketlerini de birlikte yürütüyor
-
2. Üretkenlik metrikleri (Throughput & Time Savings)
- PR throughput: GitHub, Dropbox, Webflow, CircleCI vb. birçok şirketin ortak olarak izlediği bir metrik
- Zaman tasarrufu (Time savings): Mühendis başına haftalık kazanılan zamanı ölçüyorlar (Dropbox, Monzo, Toast, Xero vb.)
- PR cycle time: Microsoft, CircleCI, Xero, Grammarly gibi şirketlerde kullanılıyor
-
3. Kalite/istikrar metrikleri (Quality & Reliability)
- Change Failure Rate: GitHub, Dropbox, Adyen, Booking.com, Webflow vb. arasında en yaygın kalite metriği
- Kodun sürdürülebilirliği / kalite algısı: GitHub, Adyen, CircleCI vb. bunu DevEx ile ilişkilendirerek değerlendiriyor
- Hata / geri alma oranı: Glassdoor (hata sayısı), Toast (PR revert rate)
-
4. Geliştirici deneyimi metrikleri (Developer Experience)
- Geliştirici memnuniyeti / anketleri (DevEx, DXI): Atlassian, Webflow, CarGurus, Vanguard vb. tarafından kullanılıyor
- Bad Developer Days (BDD): Microsoft, sürtünmeyi ölçmek için özgün biçimde ‘kötü geliştirici günü’ kavramını kullanıyor
- Bilişsel yük ve geliştirici friction: Google, eBay vb.
-
5. Maliyet ve yatırım metrikleri (Spend & ROI)
- AI harcaması (toplam ve geliştirici başına): Dropbox, Grammarly, Shopify örneklerinde olduğu gibi bazı şirketler maliyeti izliyor
- Capacity worked (kullanım oranı): Glassdoor, aracın azami potansiyeline kıyasla ne kadar kullanıldığını ölçüyor
-
6. İnovasyon / deney metrikleri (Innovation & Experimentation)
- Innovation ratio / velocity: GitHub, Microsoft, Webflow vb. inovasyon hızını metrikleştiriyor
- A/B test sayısı: Glassdoor, aylık A/B test adedini temel bir metrik olarak görüyor
- Zaman tasarrufu, PR throughput, change failure rate, etkin kullanıcı sayısı, inovasyon oranı gibi çıktı metrikleri ile kullanım davranışı metrikleri birlikte izleniyor
- Kurumlara göre metrik setleri, öncelikler ve ürün bağlamı doğrultusunda değişiyor; her derde deva tek bir metrik yok
2. Sağlam temel: AI etkisini ölçmenin özü
- Yapay zeka ile kod yazılıyor olması, iyi yazılımın ölçütlerini değiştirmiyor. Kalite, sürdürülebilirlik ve hız hâlâ temel unsurlar.
- Bu nedenle Change Failure Rate, PR throughput, PR cycle time, geliştirici deneyimi (DevEx) gibi mevcut metrikler hâlâ önemli.
- Tamamen yeni metrikler gereksiz
- Asıl önemli soru şu: “Yapay zeka, zaten önemli olan şeyleri daha iyi yapmamızı sağlıyor mu?”
- LOC veya kabul oranı gibi yüzeysel metriklerde kalınırsa yapay zekanın etkisi doğru şekilde anlaşılamaz
- Yapay zeka kullanımında tam olarak neler olduğunu anlamak için yeni hedef metriklere ihtiyaç var
- Yapay zekanın nerede, ne kadar ve hangi biçimde kullanıldığını anlayarak bütçe, araç dağıtımı, güvenlik ve compliance gibi kararlar alınabilir
- Yapay zeka metrikleri şunları gösterir:
- Yapay zeka araçlarını benimseyen geliştiricilerin sayısı ve türü nedir?
- Yapay zeka ne kadar işi ve hangi tür işleri etkiliyor?
- Maliyet ne kadar?
- Temel mühendislik metrikleri ise şunları gösterir:
- Ekibin daha hızlı ship edip etmediği
- Kalite ve güvenilirliğin artıp artmadığı / azalıp azalmadığı
- Kodun sürdürülebilirliğinin düşüp düşmediği
- Yapay zeka araçlarının geliştirici iş akışındaki sürtünmeyi azaltıp azaltmadığı
-
Dropbox örneğine bakıldığında
- Yapay zeka metrikleri
- DAU/WAU (günlük/haftalık aktif kullanıcılar)
- AI tool CSAT (memnuniyet)
- Mühendis başına zaman tasarrufu
- Yapay zeka harcaması
- Çekirdek metrikler (Core 4 Framework kullanılarak)
- Change Failure Rate
- PR throughput
- Sonuçlar
- Haftalık düzenli yapay zeka kullanıcıları = tüm mühendislerin %90’ı (sektör ortalaması olan %50’nin üzerinde)
- Düzenli yapay zeka kullanıcılarında PR merge oranı %20 arttı + Change Failure Rate düştü
- Önemli olan, benimsenme oranının kendisinden ziyade bunun organizasyon, ekip ve bireysel performansa gerçekten katkı sağlayıp sağlamadığıdır
- Yapay zeka metrikleri
3. Yapay zeka kullanım düzeyine göre metriklerin ayrıştırılması
- Yapay zekanın geliştiricilerin çalışma biçimini nasıl değiştirdiğini anlamak için çeşitli karşılaştırmalı analizler yapılıyor
- Yapay zeka kullanıcıları ile kullanmayanların karşılaştırılması
- Yapay zeka aracı benimsenmeden önce ve sonra temel mühendislik metriklerinin karşılaştırılması
- Aynı kullanıcı grubunun izlenmesi (cohort analysis) ile yapay zeka benimsenmesinden sonraki değişimlerin gözlemlenmesi
- Verileri ayrıntılı şekilde bölerek (slicing & dicing) kalıplar çıkarma
- Rol, kıdem, bölge, ana dil gibi özelliklere göre analiz
- Örneğin: junior’larda PR yazımı artarken, senior’larda review payının artması nedeniyle hızın düşmesi
- Bu sayede ek eğitim ve desteğe ihtiyaç duyan gruplar ile yapay zeka kullanımından yüksek verim alan gruplar belirlenebilir
- Webflow örneği
- Kıdemi 3 yılın üzerindeki geliştirici grubunda, yapay zeka kullanıldığında zaman tasarrufu etkisi en yüksekti
- Cursor, Augment Code gibi araçlar kullanıldığında PR throughput %20 arttı (yapay zeka kullanıcıları ile kullanmayanların karşılaştırması)
- Sağlam bir baseline ihtiyacı
- Geliştirici üretkenliği metrik temeli olmayan organizasyonlarda yapay zeka etkisini ölçmek zordur
- Core 4 framework (Dropbox, Adyen, Booking.com vb. tarafından kullanılıyor) ile hızlıca temel çizgi oluşturulabilir
- Şablon ve rehber için bkz.
- Sistem verileri, deneyim örnekleme verileri ve düzenli anketler birlikte kullanılarak güvenilir karşılaştırmalar yapılabilir
- Sürekli takip ve deneysel düşünme yaklaşımı kritik
- Tek seferlik ölçümlerin anlamı yok; eğilim ve kalıpları görmek için zaman serisi takibi yapılmalı
- Başarılı şirketlerin ortak noktası: somut hedefler belirleyip hipotezleri veriyle test etmek
- Veriye körü körüne bağlı kalmadan, hedef odaklı deneysel bir zihniyet sürdürmek
4. Sürdürülebilirlik, kalite ve geliştirici deneyimi konusunda dikkat
- Yapay zeka destekli geliştirme hâlâ yeni bir alan
- Uzun vadeli kod kalitesi ve sürdürülebilirlik üzerindeki etkisini kanıtlayacak veri yetersiz
- Kısa vadeli hız artışı ile uzun vadeli teknik borç riski arasındaki denge temel mesele
- Birbirini dengeleyen metrikler birlikte izlenmeli
- Çoğu şirket Change Failure Rate ile PR throughput metriklerini aynı anda takip ediyor
- Hız artarken kalite düşüyorsa bu, anında bir sorun sinyali işlevi görüyor
- Kalite ve sürdürülebilirliği izlemek için ek metrikler
- Change confidence: Deploy sırasında kodun kararlılığına dair geliştirici güveni
- Code maintainability: Kodun anlaşılma ve değiştirilme kolaylığı
- Perception of quality: Kod kalitesi ve ekip pratiklerine dair geliştirici algısı
- Sistem metrikleri ile öz bildirim metriklerinin birlikte kullanılması gerekli
- Sistem verileri: PR throughput, deploy sıklığı vb.
- Öz bildirim verileri: change confidence, maintainability vb. → uzun vadeli olumsuz etkileri önleyen temel sinyaller
- Düzenli geliştirici deneyimi (DevEx) anketleri öneriliyor
- Anket örneği üzerinden kalite, sürdürülebilirlik ve yapay zeka kullanımı arasındaki ilişki izlenebilir
- Yapılandırılmamış geri bildirimler de mevcut sorunları anlamak ve çözümleri tartışmak için yararlı
- Geliştirici deneyimi (DevEx) gerçekte ne anlama geliyor?
- “Masa tenisi ve bira” gibi yan haklar değil, geliştirme sürecinin tamamındaki sürtünmeyi ortadan kaldırmak
- Hedef; planlama → geliştirme → test → deploy → operasyon sürecinin tamamında verimlilik sağlamak
- Yapay zeka araçları kod yazma ve testteki sürtünmeyi azaltırken, review, incident response ve bakım tarafında yeni sürtünmeler ekleme riski taşıyor
- Saha içgörüsü (CircleCI’den Shelly Stuart)
- Çıktı metrikleri (PR throughput) ne olduğunu gösterir, ancak geliştirici memnuniyeti sürdürülebilirliği gösterir
- Yapay zeka benimsenmesi başlangıçta rahatsızlık yaratabilir; bu yüzden memnuniyet takibi, kısa vadeli sürtünme ile uzun vadeli değeri ayırt etmede temel araçtır
- Şirketlerin %75’i yapay zeka araçlarının CSAT/memnuniyetini de takip ediyor → odak, hızdan çok sürdürülebilir bir geliştirme kültürü oluşturmak
5. Özgün metrikler ve ilginç eğilimler
- Microsoft: Bad Developer Day (BDD)
- Günlük işlerdeki sürtünme ve yorgunluğu gerçek zamanlı ölçen bir kavram
- Olay müdahalesi ve compliance işlemleri, toplantı ve e-posta arasında geçiş maliyeti, iş yönetim sistemlerinde harcanan zaman gibi unsurlar günü kötüleştiren etkenler
- PR etkinliğiyle (kodlama süresi için vekil gösterge) dengelenerek, düşük değerli bazı işler olsa bile kodlamaya belli bir süre ayrılabiliyorsa gün iyi olarak değerlendiriliyor
- Hedef: AI araçlarının BDD sıklığını ve şiddetini azaltıp azaltmadığını doğrulamak
- Glassdoor: deneyler ve araç kullanım oranının ölçülmesi
- Aylık A/B test sayısı ile AI'ın inovasyon ve deney hızını artırıp artırmadığı takip ediliyor
- Power user'ları şirket içi AI evangelistleri olarak yetiştirme stratejisi de birlikte yürütülüyor
- Capacity worked (kullanım oranı): Aracın potansiyel kullanım miktarına karşılık gerçek kullanım miktarı ölçülerek benimsemenin doygunluk noktası ve bütçe yeniden tahsisi değerlendirilir
- Acceptance Rate'in düşüşü
- Geçmişte temel AI metriğiydi, ancak yalnızca önerinin kabul edildiği ana baktığı için kapsamı dar
- Bakım yapılabilirlik, bug oluşumu, kodun geri alınması, geliştiricinin hissettiği üretkenlik gibi unsurları yansıtmaz
- Şu anda en üst seviye metrik olarak pek kullanılmıyor, ancak istisnalar var:
- GitHub: Copilot iyileştirmeleri ve ürün kararlarında kullanıyor
- T-Mobile: AI kodunun gerçekten production'a ne ölçüde yansıdığını tahmin ediyor
- Atlassian: geliştirici memnuniyeti ve öneri kalitesi için yardımcı metrik olarak kullanıyor
- Maliyet ve yatırım analizi
- Çoğu şirket, geliştiricilerin cesaretini kırmamak için kullanım maliyetini agresif şekilde takip etmiyor
- Shopify, AI Leaderboard ile token tüketimi yüksek geliştiricileri kutlayan bir yaklaşım benimsiyor
- ICONIQ 2025 State of AI Report: 2025'te şirket içi AI üretkenlik bütçesinin 2024'e kıyasla iki katına çıkması bekleniyor
- Bazı şirketler işe alım bütçesini azaltıp bunu AI araçları bütçesine yeniden tahsis etme yöntemine geçiyor
- Ajan telemetrisi eksikliği
- Şu anda neredeyse hiç ölçüm yok, ancak önümüzdeki 12 ay içinde devreye alınma olasılığı yüksek
- Otonom ajan workflow'ları yaygınlaştıkça davranış, doğruluk ve regresyon oranı gibi unsurları ölçme ihtiyacı artacak
- Kod dışı faaliyetlerin ölçümündeki eksiklik
- Şu anda kod yazım desteğiyle sınırlı; ChatGPT ile yapılan planlama oturumları veya Jira issue işleme gibi alanlar pek dahil edilmiyor
- 2026'da AI kullanımı SDLC'nin tüm aşamalarına yayılacak ve ölçümün de buna göre evrilmesi gerekecek
- Kod inceleme, zafiyet taraması gibi somut faaliyetleri ölçmek kolay; soyut işleri ölçmek ise zor
- Öz bildirim temelli ölçümlerin (“Bu hafta AI ile ne kadar zaman kazandınız?”) kapsamının genişlemesi bekleniyor
6. AI etkisi nasıl ölçülmeli?
- AI Measurement Framework
- DevEx Framework ortak yazarı Abi Noda ile birlikte geliştirildi
- Yaklaşık 400 şirketten saha verileri ve son 10 yılı aşkın geliştirici üretkenliği araştırmalarına dayanarak hazırlandı
- AI metrikleri ile çekirdek metrikleri birleştirerek hız, kalite, bakım yapılabilirlik ve geliştirici deneyimini (DevEx) birlikte değerlendiriyor
- Tek bir metrik (ör. AI tarafından üretilen kod oranı) başlıklar için uygun olabilir, ancak yeterli bir performans ölçüm aracı değildir
- Nitel + nicel verinin birlikte kullanılması gerekir
- Sistem metrikleri (PR throughput, DAU/WAU, deployment sıklığı vb.) ile öz bildirim metrikleri (CSAT, zaman tasarrufu, bakım yapılabilirlik algısı vb.) birlikte toplanmalı; ancak bu sayede çok boyutlu bir anlayış mümkün olur
- Birçok şirket veri toplama ve görselleştirme için DX kullanıyor; özel sistemler kurmak da mümkün
- Veri toplama yöntemleri
- Sistem verisi (nicel): AI araçlarının yönetim API'leri (kullanım, harcama, token, kabul oranı) + SCM, JIRA, CI/CD, build ve olay yönetimi metrikleri
- Düzenli anketler (nitel): Çeyreklik / altı aylık anketlerle DevEx, memnuniyet, değişiklik güveni, bakım yapılabilirlik gibi sistem metrikleriyle yakalanması zor uzun vadeli eğilimler izlenir
- Deneyim örnekleme (nitel): Workflow içine kısa sorular yerleştirilir (ör. PR gönderiminin hemen ardından “AI kullandınız mı?”, “Bu kodu anlamak kolay mıydı?”)
- Uygulama önceliği
- Düzenli anketler en hızlı başlangıç noktasıdır: 1-2 hafta içinde ilk veriler elde edilebilir
- Perde asarken gereken hassasiyetle roket fırlatırken gereken hassasiyet farklıdır; benzer şekilde, mühendislik kararları için yeterli yön duygusu sağlayan doğruluk seviyesi de anlamlı olabilir
- Sonrasında diğer veri toplama yöntemleri de eklenip çapraz doğrulama yapılırsa güvenilirlik artar
- Ek kaynaklar
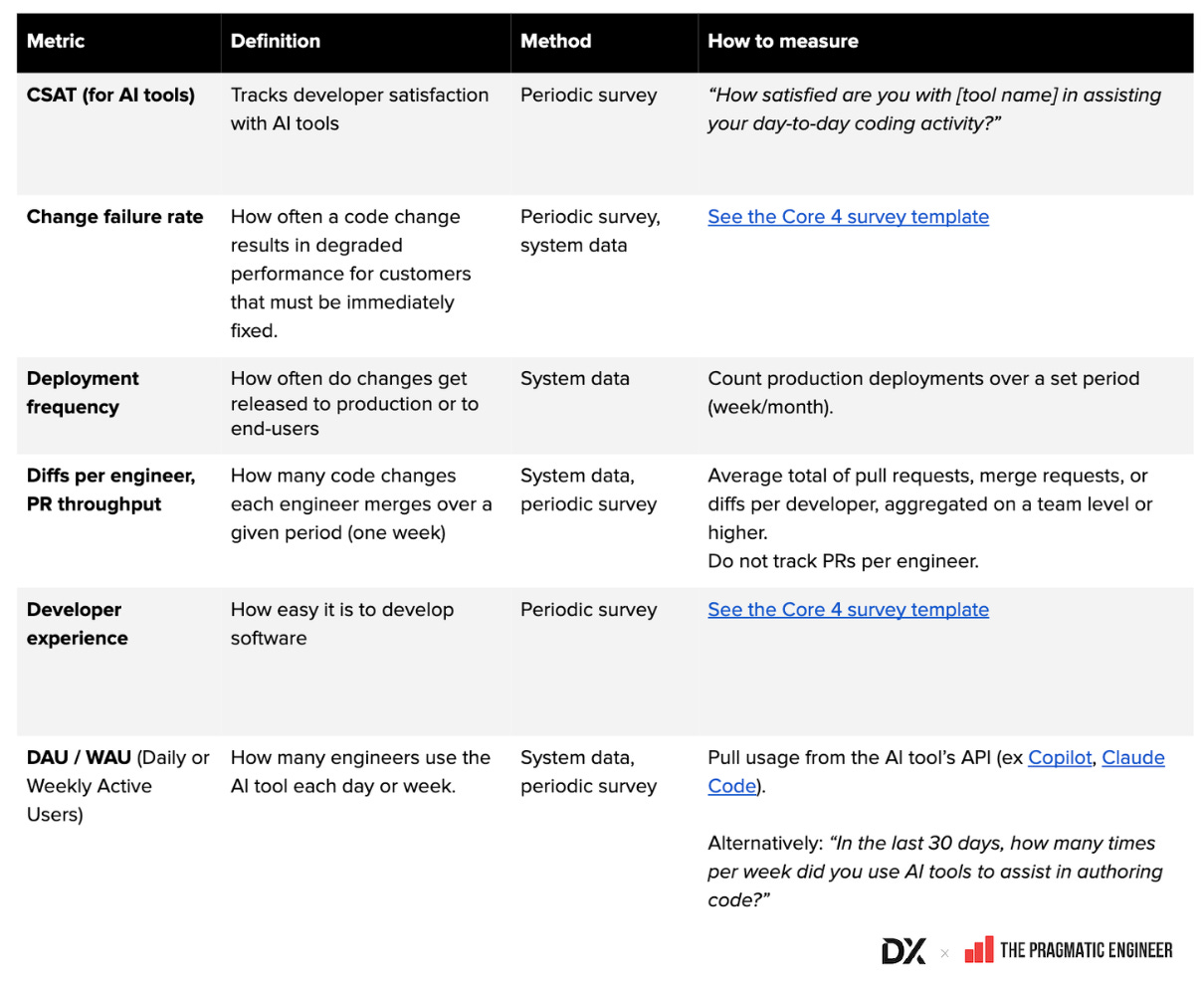
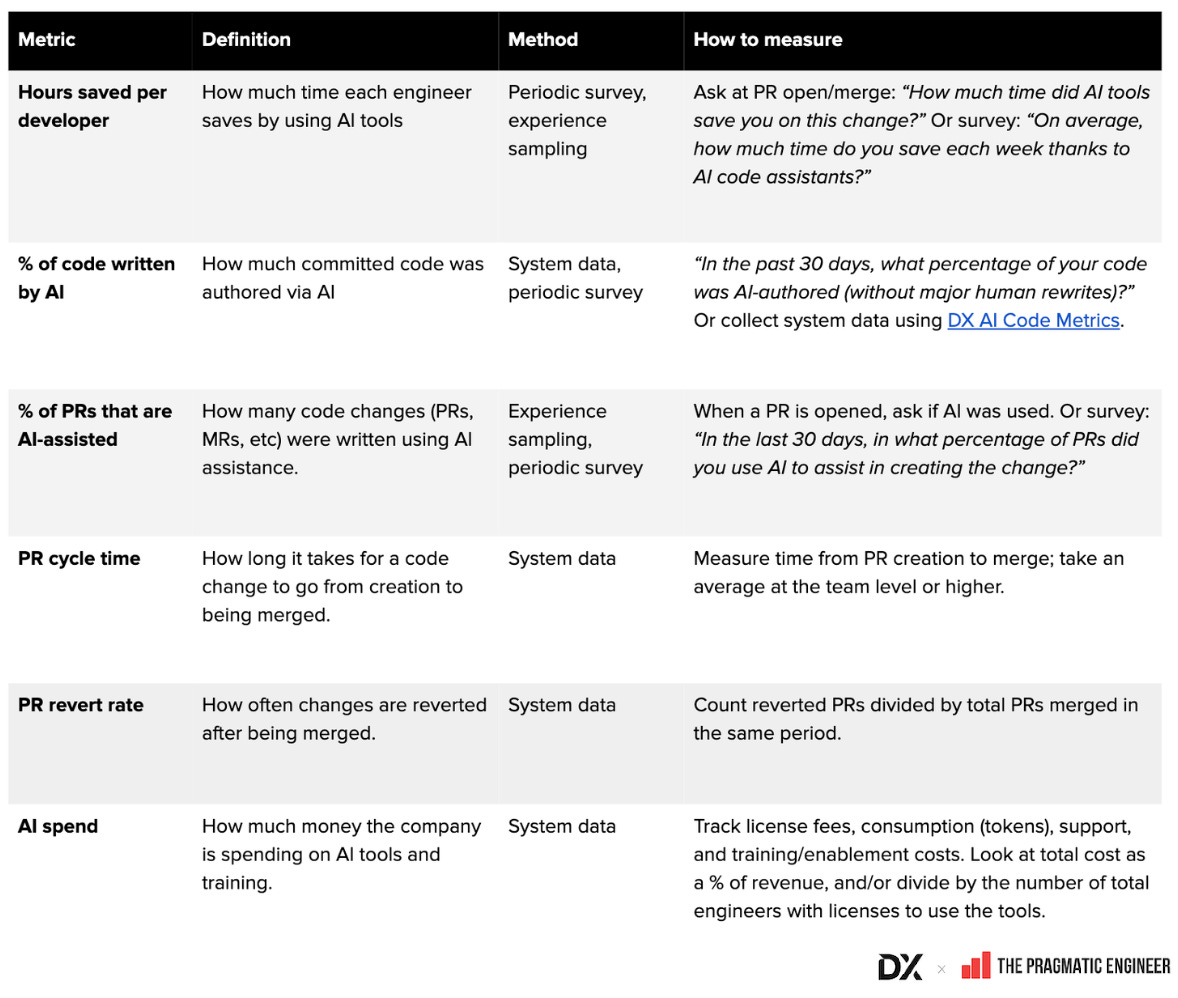
- Ortak AI metrikleri sözlüğü (Google Sheet): tanımlar, hesaplama yöntemleri ve toplama biçimleri derlenmiş durumda
- AI ve geliştirici üretkenliği metriklerine ilişkin örnek görseller
- Şirket içinde uygularken dikkat edilmesi gerekenler
- Amaç, benimsenme oranı ya da tek bir metriğin peşinden koşmak değil; yüksek kaliteli yazılımı müşterilere hızlı biçimde ulaştırma yeteneğinin gelişip gelişmediğini doğrulamaktır
- Temel soru:
> “AI, zaten önemli olan şeyleri (kalite, yayınlama hızı, geliştirici deneyimi) daha iyi hale getiriyor mu?” - Liderlik toplantılarında ele alınması gereken sorular:
- Organizasyonumuzda mühendislik başarısı nasıl tanımlanıyor?
- AI araçlarını devreye almadan önce performans verisini topladık mı? Toplamadıysak baseline'ı nasıl hızla oluşturacağız?
- AI etkinliğini AI etkisiyle karıştırıyor olabilir miyiz?
- Hız, kalite ve bakım yapılabilirlik arasında denge kuruyor muyuz?
- Geliştirici deneyimi üzerindeki etkiler görünür durumda mı?
- Sistem verisi ile öz bildirim verisini birlikte içeren çok katmanlı bir ölçüm yaklaşımı uyguluyor muyuz?
{kind=link}
{kind=link}
7. Monzo'nun AI etkisini ölçme yöntemi
- İlk benimseme dönemi
- İlk araç GitHub Copilot oldu. GitHub lisansına dahildi ve VS Code’a doğal biçimde entegre olduğu için tüm mühendisler kullanmaya başladı
- Sonrasında Cursor, Windsurf, Claude Code gibi çeşitli araçlar paralel olarak test edilirken yatırımın odağında Copilot kalmaya devam etti
- AI araçlarını değerlendirme felsefesi
- Hızla değişen araç ekosisteminde doğrudan deneyim şart
- Ekip üyelerinin yapay zekayı gerçek kod üzerinde her gün kullanması, hatta ajan yapılandırma dosyalarını bizzat hazırlayıp denemesi gerekiyor ki performans anlaşılabilsin
- Değerlendirmede nesnel metrikler (kullanım, performans) ile öznel anketler (DX memnuniyeti) birlikte kullanılıyor
- Etkiler ve hissedilen değer
- Mühendisler, yapay zeka sayesinde doküman arama·özetleme·kod anlama işlerini daha kolay yaptıklarını ve bilişsel yükün azaldığını düşünüyor
- Rekabetçi yetenek pazarında en iyi araçlar sunulmazsa geliştirici kaybı riski doğuyor → araç sağlamak başlı başına bir yetenek elde tutma stratejisi
- Ölçmenin zorlukları
- Satıcıların sunduğu sayılar kabul oranı gibi sınırlı metriklerle sınırlı kalıyor; gerçek iş etkisini anlamak zor
- Bunu A/B testleriyle tam olarak doğrulamak da pratikte mümkün değil
- Çeşitli araçların (GitHub, Gemini, Slack, Notion vb.) kullanım verilerini bir araya getirmek zor → telemetri kısıtları ve vendor lock-in başlıca engeller
- Sonuç olarak bugün için temel sinyal hâlâ geliştirici algısı
- İyi çalışan alanlar
- Migrasyonlarda büyük başarı: kod değiştirme işlerinde %40~60 civarında azalma hissediliyor
- Veri modeli açıklama ekleme gibi tekrarlı ve manuel işlerde LLM, ilk taslağı hazırlıyor, mühendis de düzeltmesini yapıyor → büyük ölçekli emek tasarrufu
- Beklenmedik dersler
- LLM maliyet farkındalığı eksikliği: gerçek token kullanımına ilişkin faturalar görüldüğünde optimizasyon ihtiyacı daha net hissedilecektir
- Örnek: Copilot’un otomatik kod incelemesi çok token tüketip az sonuç verdiği için varsayılan olarak kapatıldı, gerektiğinde opt-in modeliyle açılıyor
- AI’nin kullanılmadığı alanlar
- Müşteri verisiyle ilgili işler: hem ham hem de kimliksizleştirilmiş veriler için AI kullanımı yasak
- Hassas veri alanlarında veri sızıntısı riskini önlemek en yüksek öncelik
- Platform ekibi felsefesi
- Guardrails sağlamak: veri koruması gibi güvenli kullanım ortamları hazırlamak
- Örnek paylaşımı: başarı/başarısızlık örnekleri ve prompt kullanım deneyimlerini şeffaf biçimde paylaşmak
- İki yönlülüğü vurgulamak: olumlu ve olumsuz yanları birlikte paylaşarak dengeli bir bakış açısını korumak
- LLM sınırlarını hatırlatmak: AI’nin de insan gibi sınırlı olduğunu, bu yüzden ona aşırı güvenilmemesi gerektiğini vurgulamak
Sonuç ve çıkarımlar
- AI etkisini ölçmek hâlâ çok yeni bir alan
- Sektörde “en iyi yöntem” diye bir şey yok
- Microsoft ve Google gibi ölçek ve pazar açısından benzer şirketler bile farklı metrikler kullanıyor
- Her şirketin kendine özgü bir yaklaşımı ve bir “flavor”ı var
- Birbiriyle çelişebilen metrikleri aynı anda ölçmek yaygın bir yaklaşım
- Temsili örnek: değişiklik başarısızlık oranı (güvenilirlik) ile PR sıklığı (hız) birlikte izleniyor
- Hızlı dağıtım ancak güvenilirliği bozmadığı sürece anlamlı olduğundan, bu iki ekseni dengeli biçimde ölçmek gerekiyor
- AI araçlarının etkisini ölçmek, geliştirici üretkenliğini ölçmeye benzer derecede zor bir problem
- Üretkenlik ölçümü, sektörün 10 yılı aşkın süredir uğraştığı bir konu
- Tek bir metrik ekip üretkenliğini açıklayamaz; belirli bir metriğe optimize olmak da üretkenliğin gerçekten arttığı anlamına gelmez
- McKinsey 2023’te üretkenlik ölçüm yöntemini “çözdüğünü” duyurdu, ancak Kent Beck ve yazar buna şüpheyle yaklaşıyor → itiraz yazısı
- Henüz net bir çözüm yok, ama deney yapmak gerekiyor
- Üretkenlik ölçümü tamamen çözülmeden, AI araçlarının etkisini ölçmek de tamamen çözülemeyebilir
- Buna rağmen “AI kodlama araçları birey, ekip ve şirket düzeyinde günlük/aylık verimliliği nasıl değiştiriyor?” sorusuna yanıt verebilmek için deney yapmaya ve yeni yaklaşımlar denemeye devam etmek gerekiyor
Henüz yorum yok.